
喜报丨我院本科生何恺锋的一作论文被软件工程领域国际顶级会议FSE 2026接收
近日,在软件工程学院刘名威副教授的指导下,2023级本科生何恺锋以第一作者身份投稿的学术论文“AdaDec: A Uncertainty-Guided Lookahead Decoding Framework for LLM-based Code Generation”被软件工程领域国际顶级会议FSE 2026接收。

会议简介
ACM International Conference on the Foundations of Software Engineering 2026(FSE 2026)是由Association for Computing Machinery旗下ACM SIGSOFT主办的国际顶级软件工程学术会议。
FSE是公认的软件工程领域四大顶级会议之一,致力于展示软件工程基础理论、方法与工具方面的最新研究成果,涵盖软件开发、测试与分析、程序理解、自动化软件工程以及基于大语言模型的软件工程等前沿方向。该会议为软件工程领域最重要的国际学术会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。
论文介绍
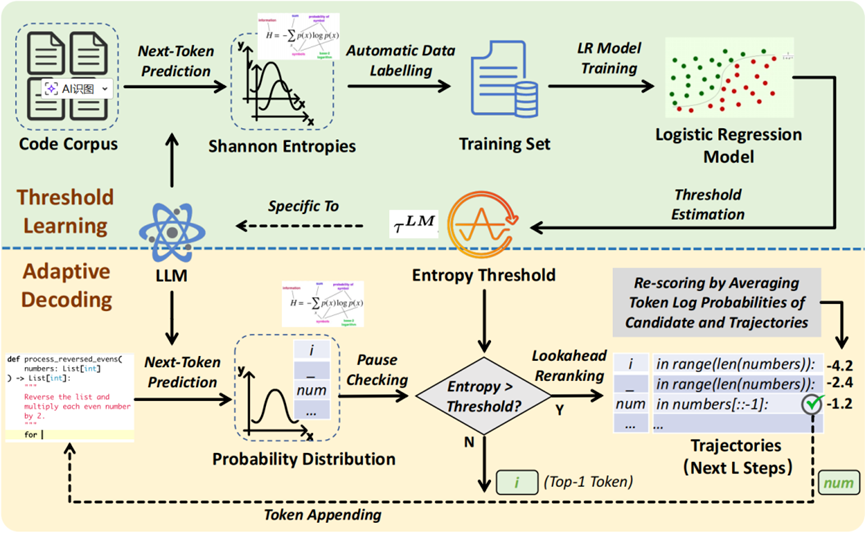
随着大语言模型(LLMs)在代码生成任务中的广泛应用,其生成质量在很大程度上依赖于解码(decoding)过程中的决策机制。然而,现有解码策略(如 greedy decoding 和 beam search)通常对所有生成步骤一视同仁,无法区分确定性较强的步骤与存在较高逻辑不确定性的关键步骤,从而容易在高不确定性位置产生“逻辑漂移”(logic drift)问题,即模型未能正确选择候选 token,导致后续生成逐步偏离正确语义 。
为了解决这一问题,我们提出了一种不确定性驱动的自适应解码框架 AdaDec(Adaptive Decoding with Uncertainty Guidance)。该方法首先通过实证分析发现:代码生成中的大量错误源于局部 token 排序错误,且 Shannon 熵可以作为衡量 token 不确定性的有效信号。基于此,AdaDec 在解码过程中引入“暂停-重排序(pause-then-rerank)”机制:当模型预测的不确定性超过阈值时,暂停当前解码步骤,并对候选 token 进行基于 lookahead 的重排序评估,从而选择更优的生成路径。同时,为提升方法的泛化能力,AdaDec 采用数据驱动方式学习模型特定的熵阈值,实现更加精细化的自适应控制 。
实验结果表明,AdaDec 在 HumanEval+、MBPP+ 和 DevEval 等多个基准数据集上均取得显著性能提升,相较于 greedy decoding,Pass@1 指标最高提升达 20.9%,并在保持较低额外计算开销的同时优于 beam search 和现有自适应(如AdapT)方法 。该工作揭示了基于不确定性的动态解码策略在提升代码生成质量中的关键作用,为构建更加鲁棒和高效的代码生成系统提供了新的思路。
指导老师
学院构建以“一人一事”项目制为基础的创新育人体系,何恺锋同学在大二年级便加入了学院刘名威副教授的课题组接受科研训练并开展学术研究。
刘名威,中山大学软件工程学院副教授、博士生导师,珠海市可信大模型重点实验室副主任,CCF软件工程专委会执行委员,“逸仙学者计划”新锐学者。2024年加入中山大学,先后于复旦大学获学士(2017)、博士(2022)学位,并完成博士后研究。研究聚焦软件工程与人工智能交叉,方向包括软件开发知识图谱及知识增强的大模型智能开发与维护。近年在TSE、TOSEM、ICSE、FSE、ASE等国际顶级期刊会议发表论文三十余篇,获ACM SIGSOFT杰出论文奖(FSE 2023)、IEEE TCSE杰出论文奖(ICSME 2018),主持或参与多项国家级项目,成果在华为、荣耀、腾讯等企业应用。

学生研究体会
大二上学期,我有幸加入了刘名威老师的课题组,开始接受较为系统的科研训练。进组初期,我面临着从课程学习向科研实践转换的挑战。科研探索与课本学习存在一定差异:课本上的专业知识相对确定且较好掌握,但在未知的科研领域,哪怕只是想向前推进一步,都需要大量的试错与严密的论证。
这项工作初期进展较为缓慢,许多初步的设想,在客观的实验数据面前都宣告失败。经过与老师们的多次讨论以及反复试错,我们逐步确立了研究方向,最终构建了不确定性驱动的自适应解码框架 AdaDec。然而,研究成果的发表同样经历了反复打磨。从初次投稿ASE受挫后的撤稿重构,到转投FSE并经历严苛的大修,我们不断根据审稿意见补充实验、完善论证,最终才获得录用。
这一系列经历让我切实体会到学术界对研究严谨性的高标准要求,也更深刻地认识到,科研没有捷径,它建立在长期的沉淀、持续的试错与严密的逻辑链条之上。


