
科研快讯丨拒绝“代码注释不对称”!多模态模型TG-CUP自动更新代码注释
● 论文标题:TG-CUP: A Transformer and GNN-Based Multi-Modal Comment Updating Method
● 发表期刊:ACM Transactions on Software Engineering and Methodology
● 作者单位:中山大学软件工程学院
● 关键词:代码注释、注释更新、协同进化、图神经网络
在软件开发中,过时代码注释如同“沉默的定时炸弹”——虽能辅助理解,但极易误导开发、引发缺陷。开发者更新代码后常忘记同步注释,导致此问题。当注释更新与代码变更关联性不高(非代码指示性更新,NCIU)时,传统基于学习的方法往往性能不足。
软件工程学院黄袁老师团队新开发的TG-CUP创新性地融合旧注释文本、代码编辑序列与AST变更差异图三大模态,通过Transformer与图神经网络协同建模,有效解决了传统方法难以处理的NCIU难题。
TG-CUP如同为代码注释装上“实时导航”,通过这种多模态融合方式,更精准地保持注释与代码同步,显著提升软件开发效率与可靠性。

一、方法论阐述
TG-CUP旨在解决代码变更后注释不同步的问题,通过自动化技术将过时注释更新为与新代码保持一致的注释。其核心创新在于采用三模态信息融合策略:(1)原始注释文本、(2)代码编辑序列、(3)AST变更差异图,并分别通过Transformer和图神经网络进行编码,最终在解码阶段通过多头注意力机制实现多模态信息融合后生成新注释,该设计使模型在常规和非代码指示性更新(NCIU)场景下均表现优异。
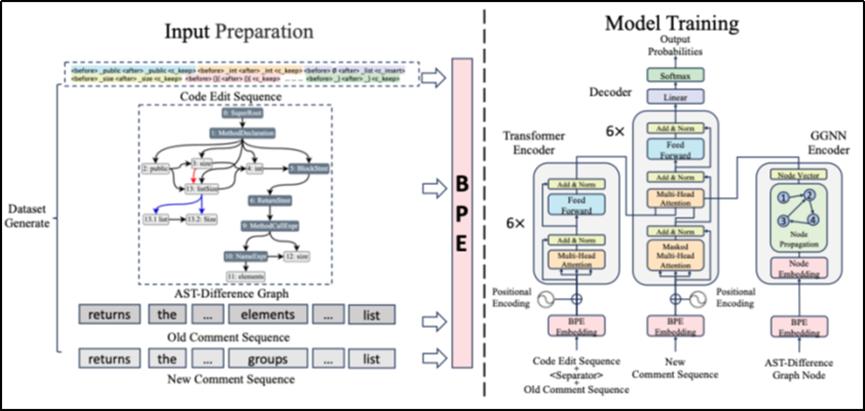
(一)文本序列输入
预处理阶段首先对旧注释进行清洗(移除URL、邮箱等无关信息),使用BPE分词得到token序列。研究数据表明大多数旧注释与新注释在词汇和结构上高度相似,这一特性使得将旧注释作为输入既有助于捕获主要语义,又能降低解码难度。对于代码变更的表示,本文对变更前后代码进行分词,基于token级对齐算法生成增、删、改三种编辑操作的token序列,最终将旧代码token、新代码token及编辑操作token组织成线性序列输入。该序列能精确反映逐token的代码变更,为模型提供细粒度修改信息。
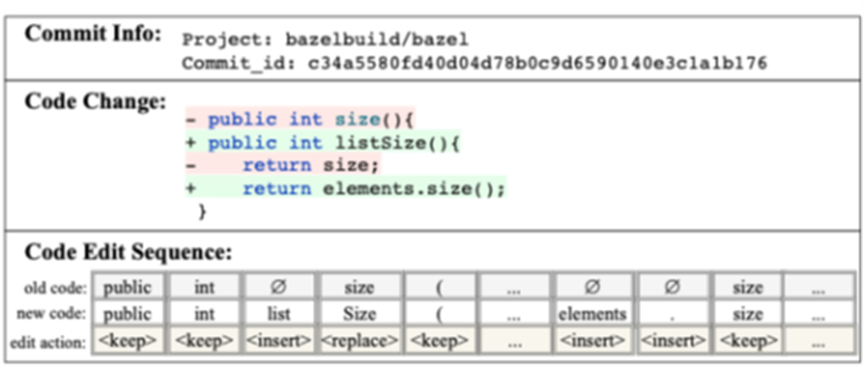
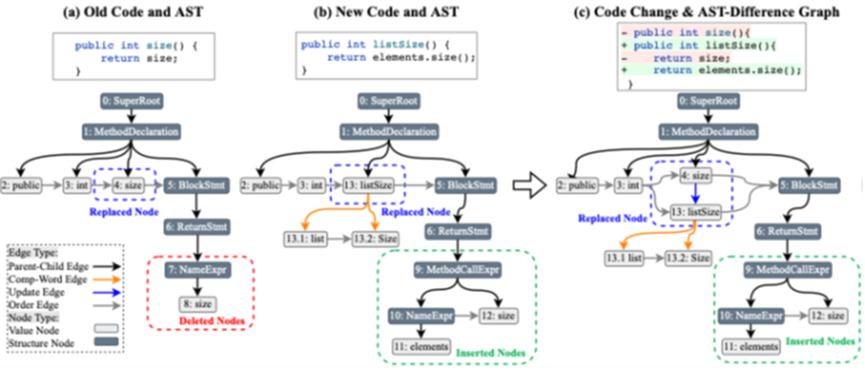
(二)AST变更差异图构建
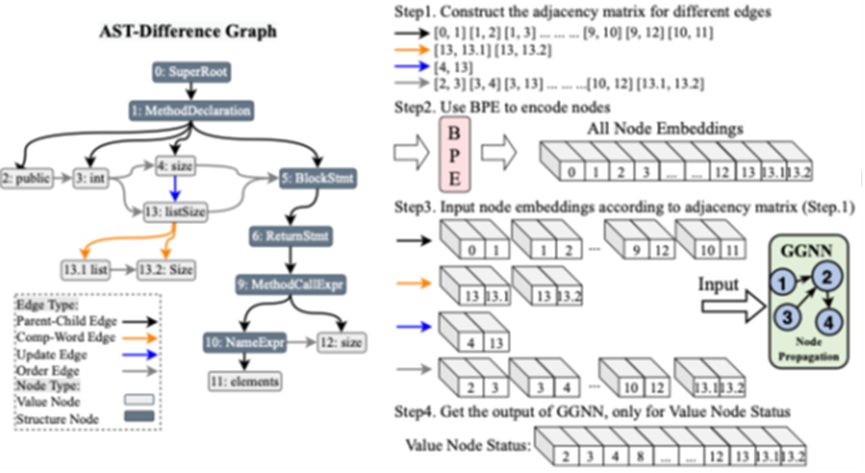
利用代码静态分析工具提取变更前后抽象语法树(AST),通过比较节点的增加、删除和更新,构建包含多种边类型(父子结构边、Token分词边、节点更新边、节点顺序边)的有向图。该图能够捕获代码结构层面的变更信息,可有效弥补文本序列的信息缺失。
(三)模型架构
首先,在输入准备阶段训练BPE模型,将三种模态的token及节点值统一映射到向量空间,以便下游模型处理。随后,将旧注释序列与代码编辑序列通过特殊分隔符连接后,输入多层Transformer编码器进行自注意力建模,有效捕获长距离依赖关系,克服基于LSTM的传统方法在长序列处理上的信息丢失问题。最后,针对AST变更差异图构建各类边的邻接矩阵,使用Gated Graph Neural Network迭代传播节点信息,最终输出值节点状态向量,使模型能够深度理解代码结构层面的变更模式。
在解码阶段,通过注意力机制融合序列编码器和图编码器的隐藏状态,整合三模态特征后通过前馈网络和Softmax计算下一个token概率。
(四)设计动机与优势
1.结构感知能力:通过AST变更差异图显式建模代码结构变更,弥补了纯序列方法对结构信息捕捉的不足。
2.长序列处理优势:Transformer的自注意力机制避免了RNN的长期依赖丢失问题,尤其适用于复杂代码编辑序列。
3.多模态融合:解码阶段的三模态注意力机制使模型能同时感知token级变更与整体结构变化,在非代码指示性更新(NCIU)场景中表现尤为突出。
二、实验与分析概述
为了全面评估TG-CUP的性能,本文将其与三种代表性方法进行了对比:CUP(基于Seq2Seq的早期方法)、HEB-CUP(启发式规则驱动的注释替换方法)、HAT-CUP(结合RNN与结构注意力的混合模型)。
● 实验结果:
TG-CUP 在测试集上的表现达到30.29% 的准确率,与最先进的HAT-CUP 相比提升了5.16个百分点。这表明通过融合旧注释、代码编辑序列和 AST 变更差异图三个模态的信息,TG-CUP能够更准确地捕获注释更新需求并生成与开发人员编写一致的注释。

为验证AST变更差异图的实际贡献,本文进行了消融实验。实验表明在去掉AST变更差异图后,TG-CUP的准确性下降了4.3个百分点,其他评价指标同步显著降低。这一结果充分证明AST变更差异图有效补充了序列表示的不足,使模型在面对复杂代码更新时更具敏感性与鲁棒性。

在非代码指示性更新(NCIU)场景下,在7,256条NCIU样本上的实验结果:TG-CUP准确率为27.65%,较HAT-CUP提升了14.17个百分点,这一结果表明,即使代码变更未直接提示注释更新需求,TG-CUP仍能通过多模态推理生成逻辑一致的注释。

总体而言,上述实验结果表明TG-CUP在广泛的对比和消融实验中均取得了显著优势,特别是在那些传统方法难以处理的复杂或隐含语义变更场景下展现了出色的能力,进一步验证了引入本文提出的AST变更差异图和图神经网络编码对于注释更新任务的重要意义。
三、应用前景
TG-CUP通过提出AST变更差异图表达代码结构变更信息,并结合Transformer与图神经网络在编码阶段分别处理序列与结构输入、在解码阶段通过多头注意力融合三模态信息,显著提升了过时注释更新任务性能,尤其是在非代码指示性更新场景下表现突出,为自动注释维护提供了更可靠的技术手段。
其广阔的应用前景主要体现在:
1.提升注释智能维护水平:通过持续优化AST差异表示和引入大语言模型的强大语义理解能力,TG-CUP有望成为更精准、更“懂”代码的自动化注释维护引擎,显著降低人工更新成本与错误率。
2.拓展应用广度:未来可扩展支持多种编程语言、跨项目迁移学习,甚至探索交互式注释更新模式,使其成为通用、灵活的注释管理解决方案。
3.赋能开发实践: 通过深入的用户研究验证其对开发效率和代码质量的实际提升效果,推动TG-CUP技术真正落地,融入开发者的日常工具链,为构建更可靠、高效的软件开发环境提供核心支持。
● 联系方式:黄老师
huangyuan5@mail.sysu.edu.cn


